El uso de la inteligencia artificial hace que los textos se entiendan en su contexto, pero puede generar sesgos y distorsiones. Como profeta, Warren Weaver era malo, pero como estratega era un genio. Cuando en los años 50, este matemático estadounidense vaticinó que las máquinas serían capaces de traducir automáticamente en el plazo de cinco años sus colegas arquearon la ceja. Y los inversores aflojaron la cartera. Puede que Weaver se viniera arriba, pero lo hizo con un propósito: conseguir que le financiaran una investigación que hoy aún se está perfeccionando: la traducción automática.
 |
El pasado mes de enero, Google anunció que su servicio de traducción, Google Translate, será capaz de realizar traducción simultánea oral. Este hito conseguiría que dos personas se entendieran hablando distintos idiomas sin necesidad de escribir previamente lo que quieren traducir, como hasta ahora. Los cascos de la compañía serán capaces de susurrarnos al oído en nuestra lengua todo lo que se habla, pongamos, en un bar de Jakarta. Se cumple así una de las predicciones con las que lleva décadas fantaseando la ciencia ficción, desde Star Trek hasta Guía para el autoestopista galáctico. Los inversores y los compradores ya están listos para aflojar la cartera, pero en esta ocasión los expertos no han mostrado sorpresa alguna. La traducción automática lleva un par de lustros cambiando la forma de entender (y de entenderse en) el mundo. Esto es solo un paso más.
Las declaraciones de Weaver dieron el pistoletazo de salida, y el anuncio de Google podría suponer el esprint final en una maratón que dura ya 80 años. Los traductores automáticos detectan 180 lenguas, hacen que podamos leer (aún sin mucha precisión) toda la web, limitan las situaciones de incomunicación en los viajes y prometen un futuro que difumine las barreras lingüísticas, culturales e incluso de clase. Pero antes de analizar las potencialidades futuras merece la pena analizar los riesgos presentes.
“Si no lo sabes usar, Google Translate puede hacer que hables peor inglés”, confirma Celia Rico, experta en tecnologías de la traducción de la Universidad Europea de Madrid. “Se basa en un corpus de palabras y estas pueden ser limitadas, degenerando el lenguaje. No podemos limitarnos a usarlo pensando que todo lo que sale de ahí es perfecto”. Rico es traductora, pero su aseveración no surge de una rivalidad mal entendida. De hecho ella lleva 30 años estudiando la traducción automática con pasión. “Todo el mundo nos imagina con una pluma y un diccionario, pero la de traductor es una profesión muy tecnológica”, explica con sorna. “Casi todos usamos herramientas de traducción automática, nos hacen el trabajo más fácil, lo que pasa es que hay que saber usarlas”.
Entonces, ¿cómo deberíamos usar Google Translate? “Si es sobre un idioma que conocemos nos puede servir como una primera pasada, casi como inspiración”, asegura Rico. “También nos puede ayudar si no conocemos ciertas palabras”. A partir de aquí hay que revisar, modificar y pulir el texto. Y esto, concluye la traductora, no lo puede hacer una máquina.
El hacedor de la máquina, irónicamente, se muestra de acuerdo. Desde Google insisten en que su herramienta no va a sustituir jamás la labor de un buen traductor, y cuando se le pide un consejo para los usuarios anuncian: “Google Translate funciona mejor cuando se trata de fragmentos cortos de texto, como menús, letreros o artículos, y puede resultar muy útil en conversaciones breves cuando necesitamos, por ejemplo, preguntar por una dirección, verificar qué ingredientes lleva un plato o averiguar el precio de algo. No pretende reemplazar la fluidez en otro idioma”.
Otro extremo a tener en cuenta al usar esta herramienta es que las formas de expresarse difieren según el idioma. “Puede que la traducción sea exacta, pero muchas veces al leerla te das cuenta de que hay algo que no está bien”, considera Rico. “Por ejemplo, en el español nos explayamos más sobre una misma idea, damos más rodeos, mientras que el inglés utiliza frases más cortas y directas. La gente razona de forma distinta según el idioma y esto se nota en la manera de estructurar los textos”. Ahí es donde entra en juego la labor de un buen traductor, para cambiar la literalidad sin alterar el espíritu de un texto.
Carmen Torrijos lleva toda la vida dedicada a hacer que nos entendamos mejor. Antes lo hacía mediando entre personas de diferentes lenguas. Ahora lo hace mediando entre humanos y máquinas. Esta antigua traductora se ha reciclado en lingüística computacional, labor que ejerce para el Instituto de Ingeniería del Conocimiento. Por eso tiene una visión más global de la traducción realizada por las máquinas.
Para explicar su idea acerca de esta tecnología tira de una anécdota: “En una ocasión pregunté a Google Translate por la traducción exacta al inglés de la expresión “trata de personas”, y me respondió “Is about people” (”va sobre las personas”). Entonces acudí al traductor DeepL, que respondió “human trafficking” (”tráfico de personas”). La diferencia era grande, pero ambas respuestas eran estrictamente válidas “Solo yo podía decidir cuál era la correcta, porque conocía el carácter del texto, el contexto y el cliente”. Por eso, ella recomienda hacer una lectura comprensiva del texto a traducir antes de darle al botón y confiar en que las máquinas hagan su magia.
La burocracia es la nueva piedra Rosetta
Esta magia, sin embargo, es cada vez más sofisticada. En sus últimas versiones los traductores automáticos tienen en cuenta el contexto antes de traducir. “Creo que el gran cambio sucedió en 2014, cuando Google empezó a utilizar la red neuronal para la traducción”, reflexiona Rico. Hasta entonces, los traductores automáticos se basaban en una traducción sintáctica y estadística, entendiendo las palabras de forma aislada. El uso de la inteligencia artificial ha hecho que empiecen a entender los textos como un entero, poniendo en contexto los detalles.
Para conseguirlo, las empresas tecnológicas alimentan a los algoritmos con una enorme cantidad de textos traducidos a varios idiomas. Y buscando en las bases de datos disponibles han encontrado un filón en el rincón más insospechado de internet: donde se apolilla la burocracia internacional. Los tratados de comercio, los protocolos de las Naciones Unidas o las leyes de la Unión Europea, escritas en decenas de idiomas de los países miembros, son el alimento perfecto para estos algoritmos. La burocracia es la nueva piedra Rosetta. Quizá por eso los traductores automáticos se muestran mucho más fiables en el lenguaje formal y académico, y fallan más a la hora de traducir expresiones y jerga callejera, que además está en constante evolución.
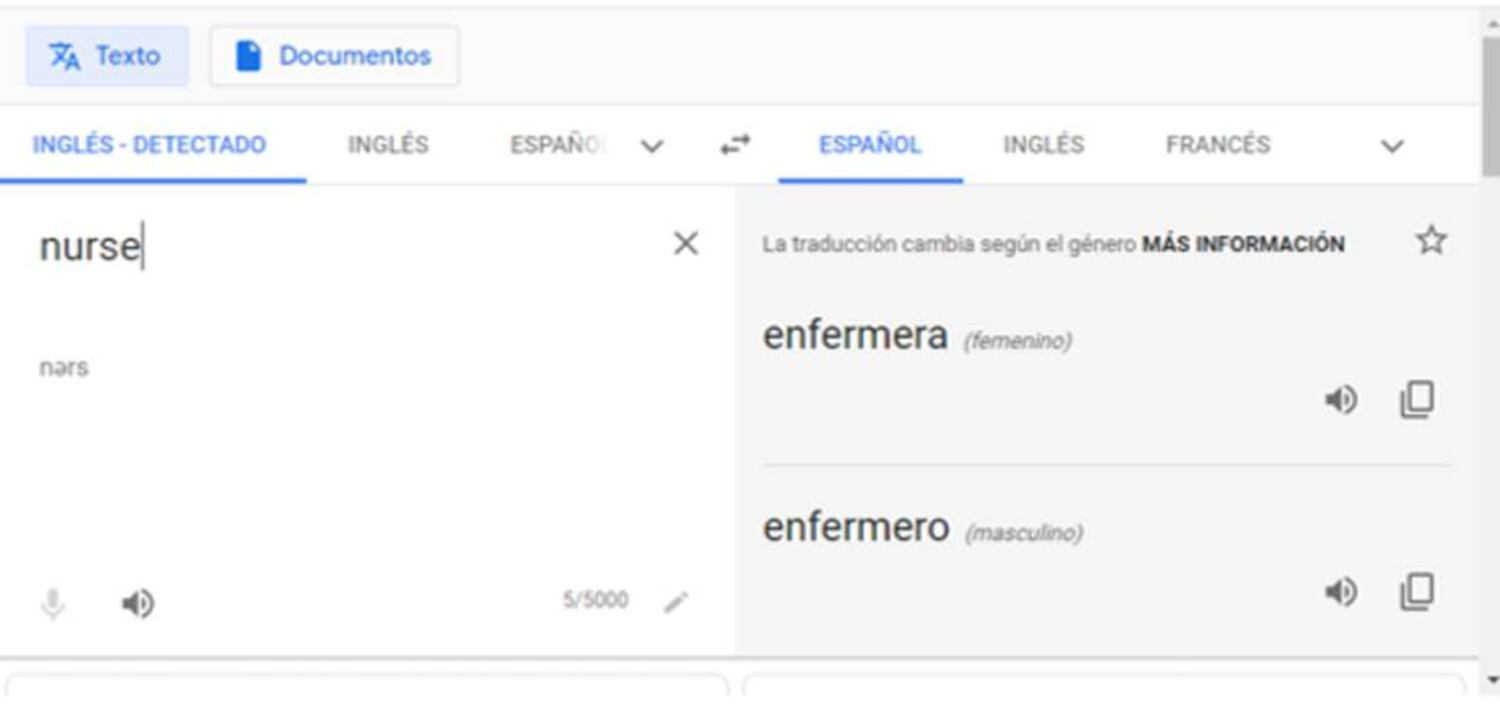
Esta forma de entrenar a los traductores automáticos puede dar lugar a sesgos y distorsiones. “Por ejemplo, si ha visto textos de política para entrenar o aprender, traducirá bastante mal unos textos de medicina”, explica Marta R. Costa-Jussà, investigadora de la Universidad Politécnica de Cataluña. “También puede amplificar los sesgos de género”, opina. Un ejemplo: en inglés, los nombres no tienen género, así que las profesiones son neutras. Pero a la hora de traducirlas a otras lenguas, por ejemplo a las de ascendencia latina, se les tiene que asignar un género. Y este reproduce lo que ha leído en Internet. Así, durante muchos años, los doctores han sido hombres y las enfermeras mujeres. En 2018, Google Translate corrigió este problema añadiendo una doble ventana con las traducciones en ambos géneros. Sin embargo, como denunciaba Algorithm Watch, algunos sesgos machistas han sobrevivido al cambio.
Otro de los efectos secundarios que tiene el alimentar a la inteligencia artificial con textos y audios disponibles en la red es la diferencia que hay entre idiomas. Obviamente no hay la misma cantidad de textos en kazajo de los que hay en japonés. Por lo tanto la traducción no funciona igual de bien. Esto se traslada, en menor medida, a lenguas intermedias. “Los reconocedores de voz funcionan mejor en alemán que en finlandés. La traducción automática entre inglés y portugués es significativamente mejor que la se puede dar entre holandés y español”, asegura Costa-Jussà. Precisamente ella está trabajando para que deje de ser así. No lo quiere conseguir a través de las palabras sino a través de los números.
El proyecto LUNAR, que dirige Costa-Jussà, pretende crear una especie de esperanto matemático. “Nuestra idea es encontrar una representación matemática del lenguaje, hablado y escrito”, explica la investigadora. “Los sistemas actuales de traducción utilizan algoritmos de aprendizaje profundo que transforman el lenguaje en una representación matemática”. Lo que LUNAR pretende hacer es utilizar la capacidad de abstracción de estos algoritmos y conseguir una representación universal del lenguaje. Reducir un idioma a una fórmula. Esta representación permitirá tener sistemas de traducción automática que mejoren la calidad de traducción de idiomas más minoritarios en los que la traducción aún no es muy buena. O como los llama Costa-Jussà “idiomas de pocos recursos”.
Proyectos como LUNAR pretenden seguir rompiendo las barreras idiomáticas, pero no quieren (ni pueden) sustituir el proceso de aprender un idioma o la labor humana de traducirlo. La riqueza cultural, personal y lingüística que supone aprender una nueva lengua. Decía Umberto Eco en su libro Dire quasi la stessa cosa (traducido por Google y por Debolsillo como Decir casi lo mismo) que la traducción es una cuestión de negociación, no se puede reducir a un puñado de fórmulas y algoritmos. Tampoco parece que sea esa la intención de estas herramientas y de los investigadores que las mejoran. “No buscamos reemplazar a los intérpretes y traductores o disuadir a alguien de aprender un nuevo idioma”, aseguran desde Google. “Nos enfocamos en romper las barreras del idioma y facilitar la comunicación de las personas. El lenguaje es más que palabras, y apoyamos y alentamos de todo corazón el aprendizaje de nuevos idiomas y de diferentes culturas”.
Warren Weaver no solo era un gran estratega, también fue un coleccionista voraz. El matemático estaba obsesionado con Alicia en el país de las maravillas. Llegó a acumular hasta 160 versiones del libro de Lewis Carroll en 42 lenguas distintas. Incluso escribió un libro, Alice in many tongues, analizando la calidad de las versiones, centrándose especialmente en lo que consideraba más difícil de traducir, los juegos de palabras y bromas lógicas del Sombrerero Loco. Algo que, pensaba, jamás sería capaz de traducir con soltura una máquina. De momento la realidad parece darle la razón. Aunque ya hemos dicho que como profeta, Weaver no fue especialmente bueno.
Fuente; El Pais
No hay comentarios:
Publicar un comentario